

Welcome to the long-context race
Two heavyweight LLM vendors made waves this month. Meta announced Llama 4 model herd, boasting a 10 million–token context window. OpenAI countered with GPT-4.1 available through their API, now featuring 1 million tokens.
In brief, Meta introduced three new multimodal models: Behemoth (large), Maverick (medium), and Scout (small). According to Meta, Behemoth outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro and is still training.
Key highlights from Meta (Llama 4):
- The new models are natively multimodal, which means they were built from the ground up to handle multiple input types, including both text and images. This can enable more versatile tools, such as visual search, image analysis, etc.
- A new "Mixture of Experts" architecture activates only the necessary model components for a task, each responsible for specific topics (such as programming, history, culture, literature, etc.). This means faster performance, reduced load, and lower infrastructure costs.
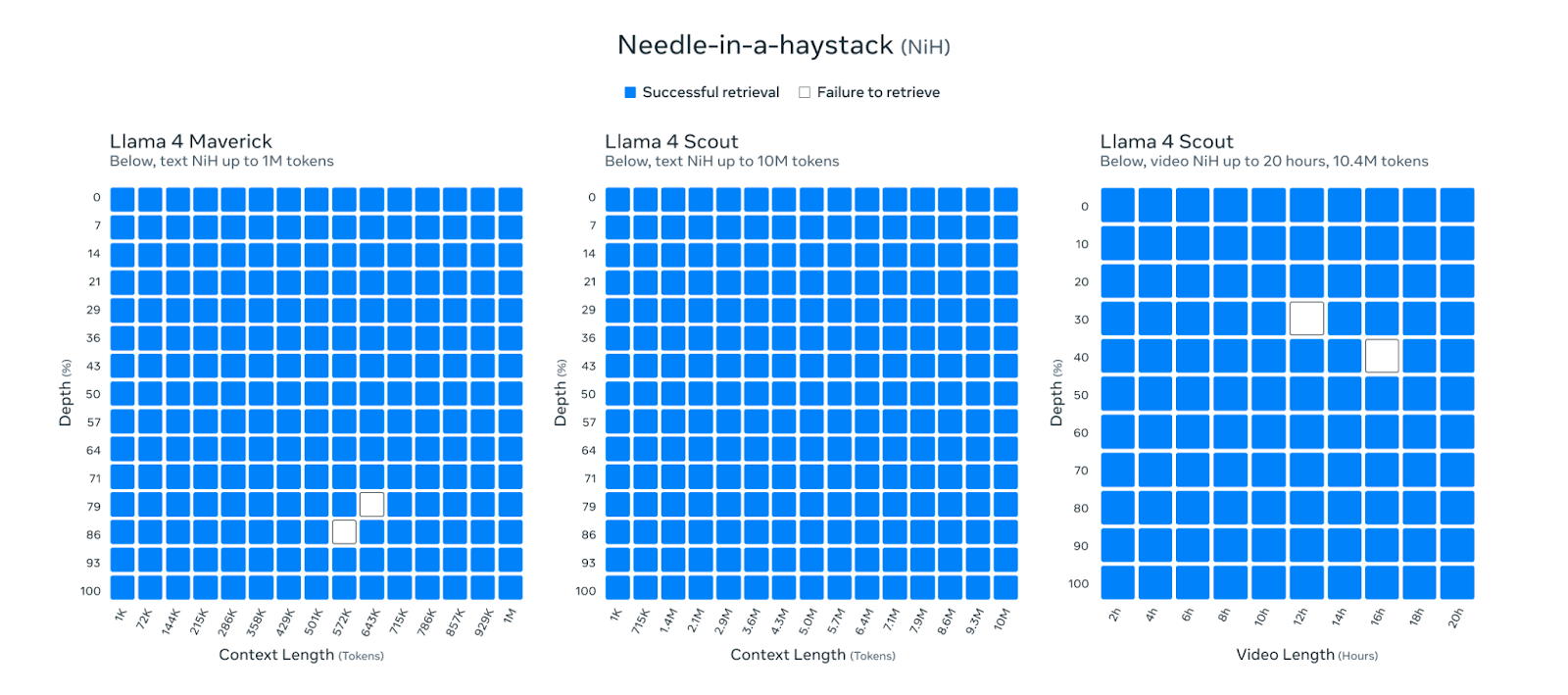
- The models can handle up to 10 million tokens of information. A token is a unit of text—typically, a word or part of it. This means the models can work with contexts made up of extensive documents (e.g., compliance papers or academic research) and complex, huge datasets.
In its turn, OpenAI added three new models to its API: GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano. According to OpenAI’s benchmarks, GPT‑4.1 outperforms GPT‑4.5 in many scenarios or provides comparable results.
Key highlights from OpenAI:
- the gradual deprecation of the GPT-4.5 preview (to be sunset on July 14, 2025)
- a drop in prices—with the gpt-4.1-nano model offered at ~$0.12 per 1M tokens
- managing up to 1 million tokens of information
The announcements opened a new, “million-token” era of LLMs, providing new possibilities for businesses.
Why care?
The introduction of gpt-4.1-mini and gpt-4.1-nano is OpenAI's answer to increasing competition in the LLM space. As other vendors push the envelope on cost efficiency and model diversification, OpenAI had no choice but to roll out these more affordable options. Indeed, $75–$150 for 1 million GPT-4.5 tokens was too much.
However, the large-context capabilities are the main part of the announcements. Here’s how a million-tosen context window and multimodal support translate into real business value:
1. Customer support
Both Llama 4 and GPT-4.1 can analyze images (e.g., a photo of a broken product), reading labels or serial numbers, understanding the text of the complaint, and providing an intelligent response, not just canned replies. It can handle global customers by keeping track of long conversations and switching languages when needed. Business value: drastically reduced support costs, boosted customer satisfaction, and automated complex ticket handling.
2. Document and contract analysis
Both models can read long documents and pull key terms, summarize contracts, highlight risks, or compare across multiple papers. 10 million tokens can be translated into hundreds or thousands of pages. Input can include scanned PDFs, typed text, or images. Business value: saved time on due diligence, procurement, and regulatory compliance, as well as reduced legal review costs.
3. Content creation
You can upload a product photo or product specs—and the models will generate blog posts, social media captions, ads, and even multilingual versions. Custom materials can be aligned with your brand’s voice and tone, guided by your internal style guides. Business value: faster marketing campaign rollouts, consistent brand messaging, and localized content at scale.
4. Enterprise search and knowledge management
Most likely, your internal documents live in 10+ different systems. Llama 4 and GPT-4.1 can process everything—emails, docs, slide decks, spreadsheets, images—and answer questions like, “What’s our current contract term with Vendor X?” Even if that’s buried on page 173 of a PDF or somewhere within thousands of PDFs. Business value: boosted employee productivity and chaos turned into clarity across departments.
Llama 4 vs. GPT-4.1
So, what are the differences between the two? The table below sums it all up.
Companies can process large documents now and in more detailed contexts, but it’s not only that.
As LLMs get more powerful with larger context windows, they are beginning to take over some of the tasks that were traditionally the strength of RAG systems. Result? Some startups built entirely around a very simple AI layer are now vulnerable. When LLMs can ingest 1–10 million tokens, a smart search engine isn’t a sufficient advantage anymore. If you're just a vector database with a prompt template—yes, you're in trouble.
In this situation, startups can focus on scaling faster and adding more value to their products. A small startup that can deliver quickly always has a chance to outpace large and rigid enterprises, at least in its niche.
For companies that considered adopting RAGs for generative AI, analytics, or automation but found this difficult, now is the time to move more rapidly with million-token LLMs.
If you want to find out what you should do next — and how — book a call, and I’ll guide you through the options available. This is completely free and without any obligation, and unlike free GPT chats, you won’t hit a token limit after a few deeper answers during the call.
